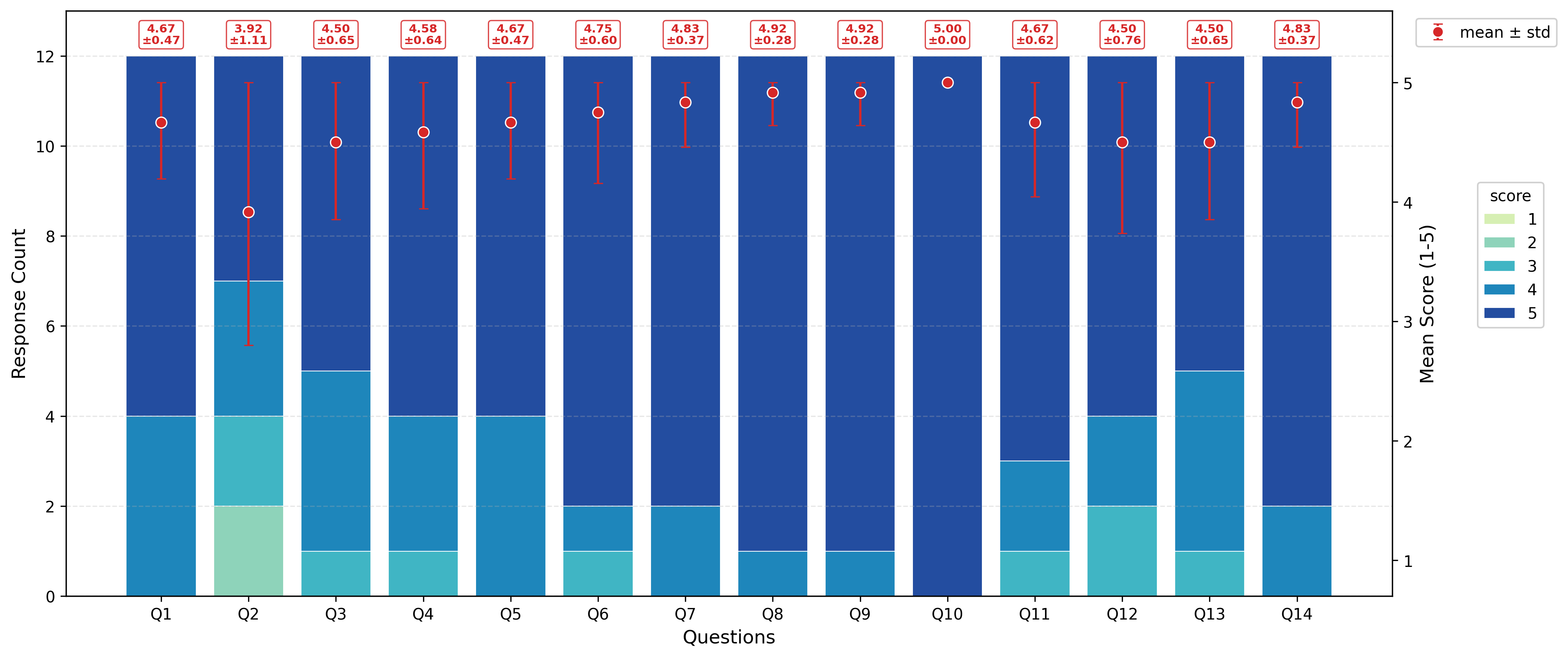
System Overview
HiLSVA adopts a multi-agent architecture centered around a lead orchestrator that coordinates a set of specialized sub-agents, and is designed around five pillars that keep the human in control throughout the SciVis workflow:
(a) Mixed-initiative agentic architecture: An orchestrator interprets user intent, constructs explicit stepwise plans, and coordinates specialized agents with bidirectional human–agent interaction.
(b) Specialized visualization agents: A ParaView agent (direct control via MCP), a code agent (SciVis Python generation with RAG and iterative error correction), a file surfer, and a web surfer execute SciVis actions and report outcomes back to the orchestrator.
(c) Stepwise control & provenance tracking: Workflows are represented as editable steps that record planned and executed actions, software states, and visualization outputs for undo, branching, and reuse.
(d) Sandboxed execution environments: Tool interactions run in isolated Docker containers, enabling safe, parallel execution across sessions.
(e) Learn-at-test-time (LTT) with human feedback: A self-improving agent reflects on execution outcomes, assesses uncertainty, queries users when needed, and updates a knowledge repository during inference.
The current implementation runs ParaView as the visualization engine, uniquely supporting multiple interaction modalities on the same instance — MCP tool calls, generated Python scripts, and direct GUI manipulation. The architecture itself is backend-agnostic.
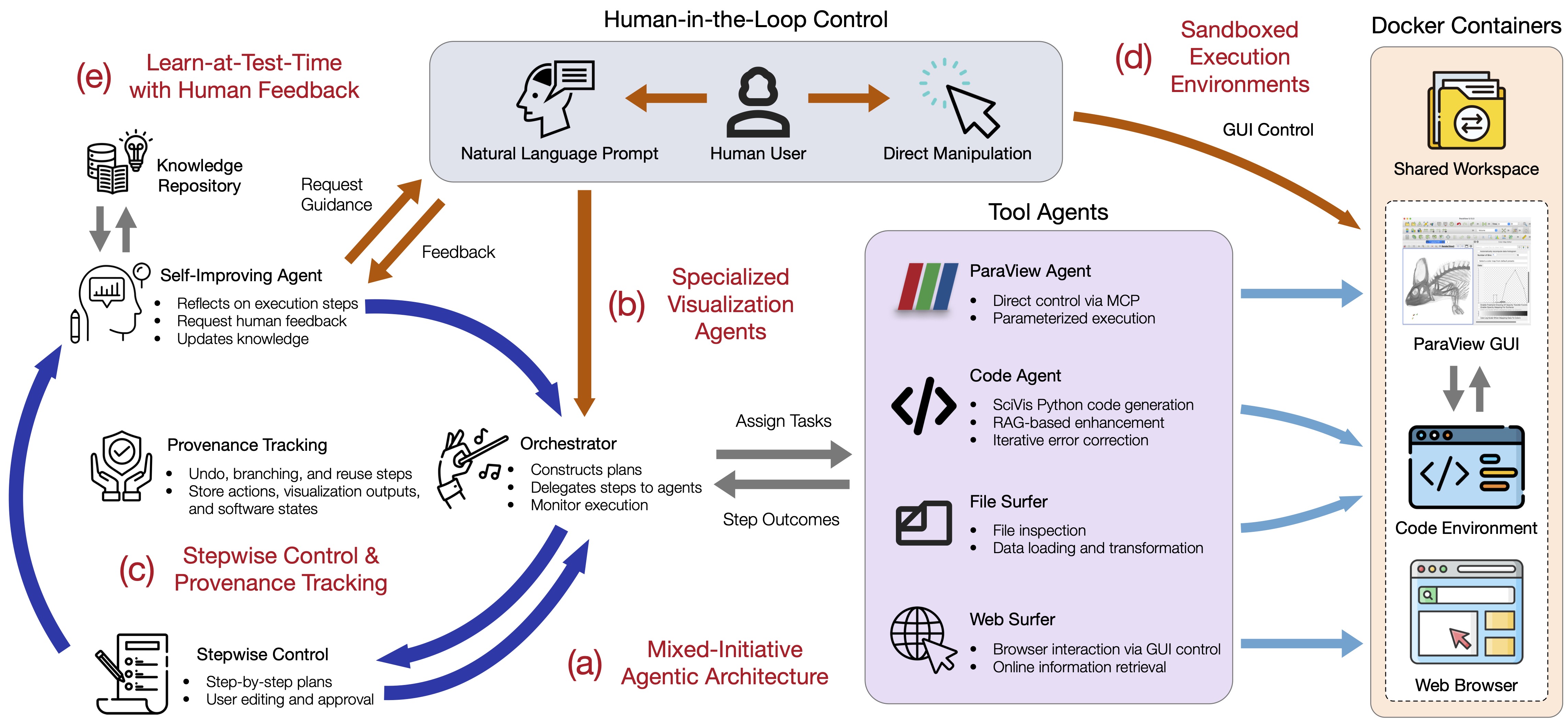
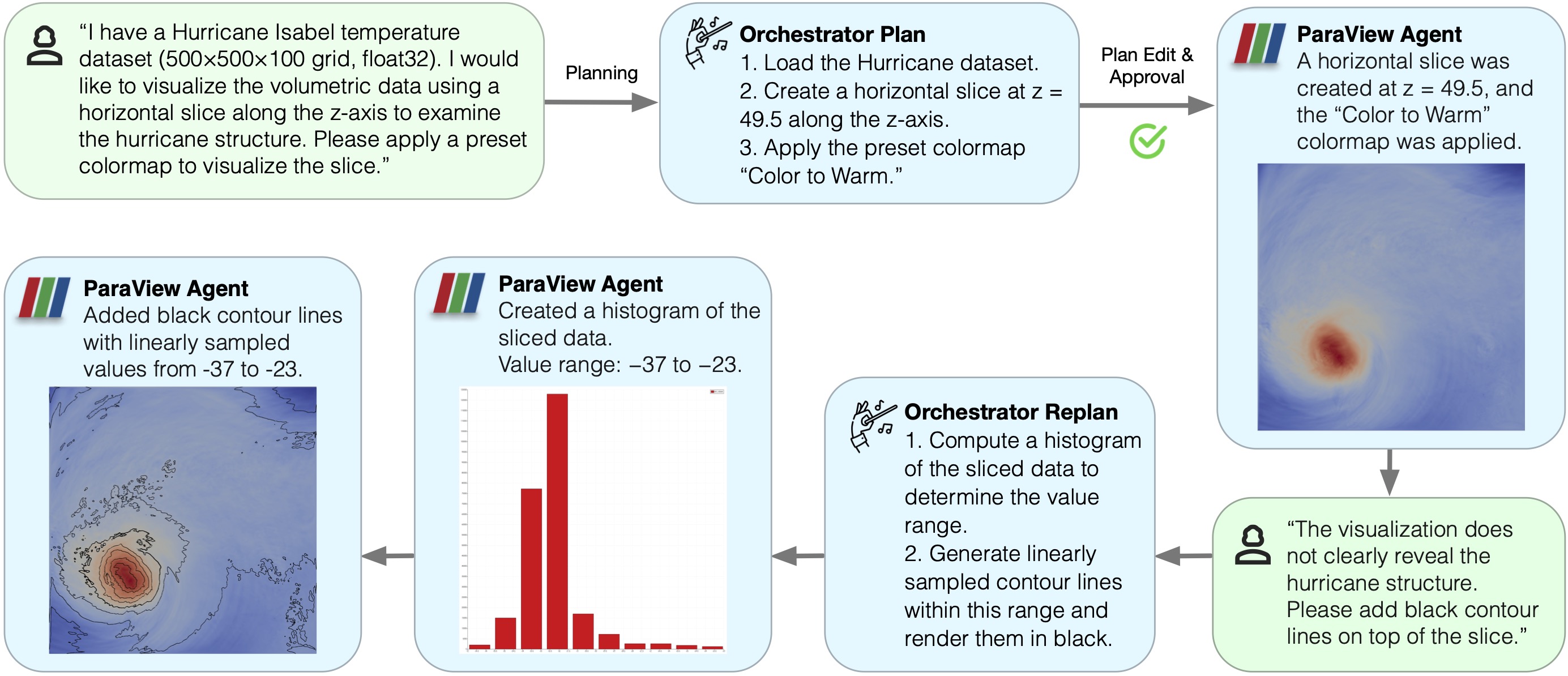
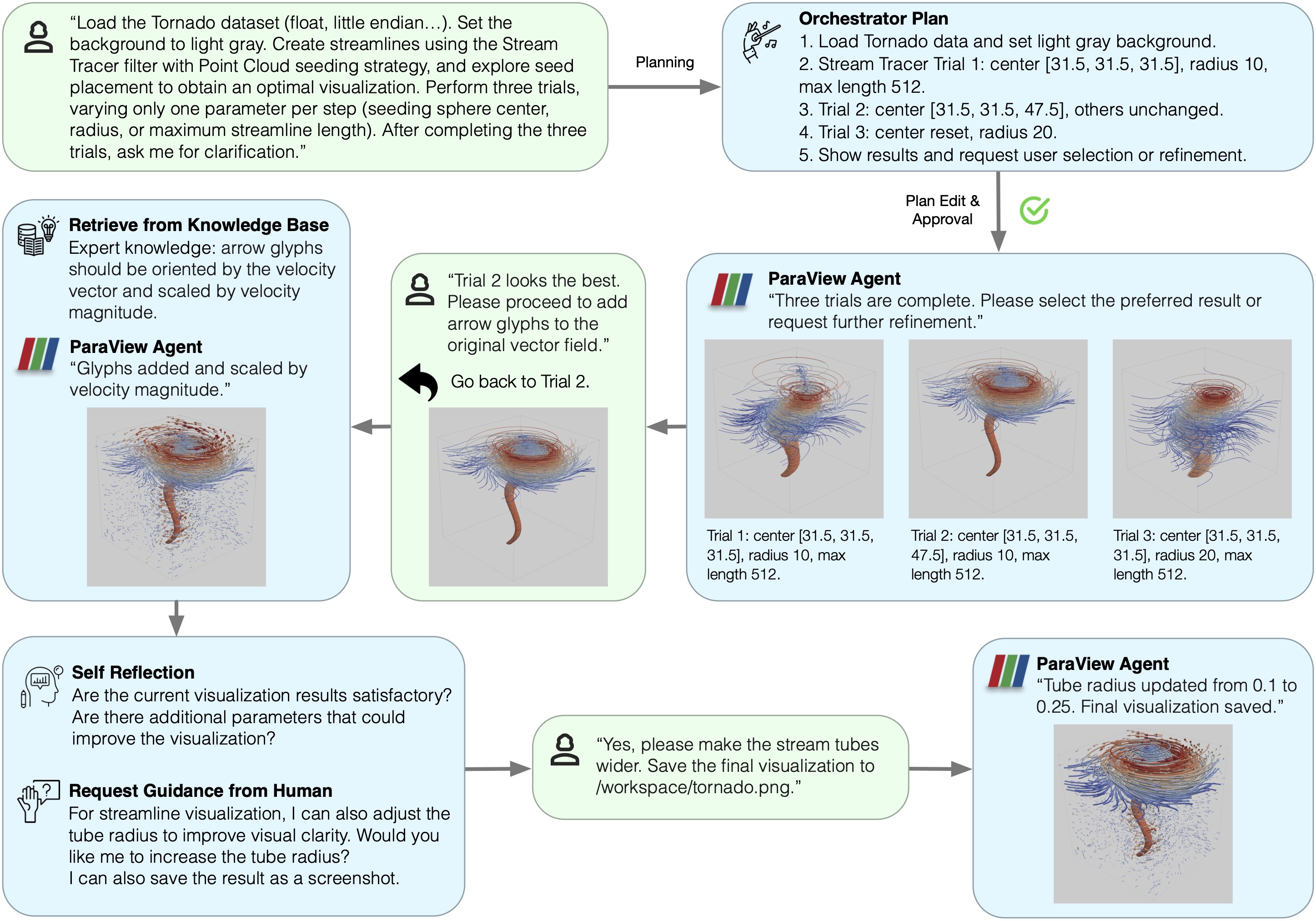
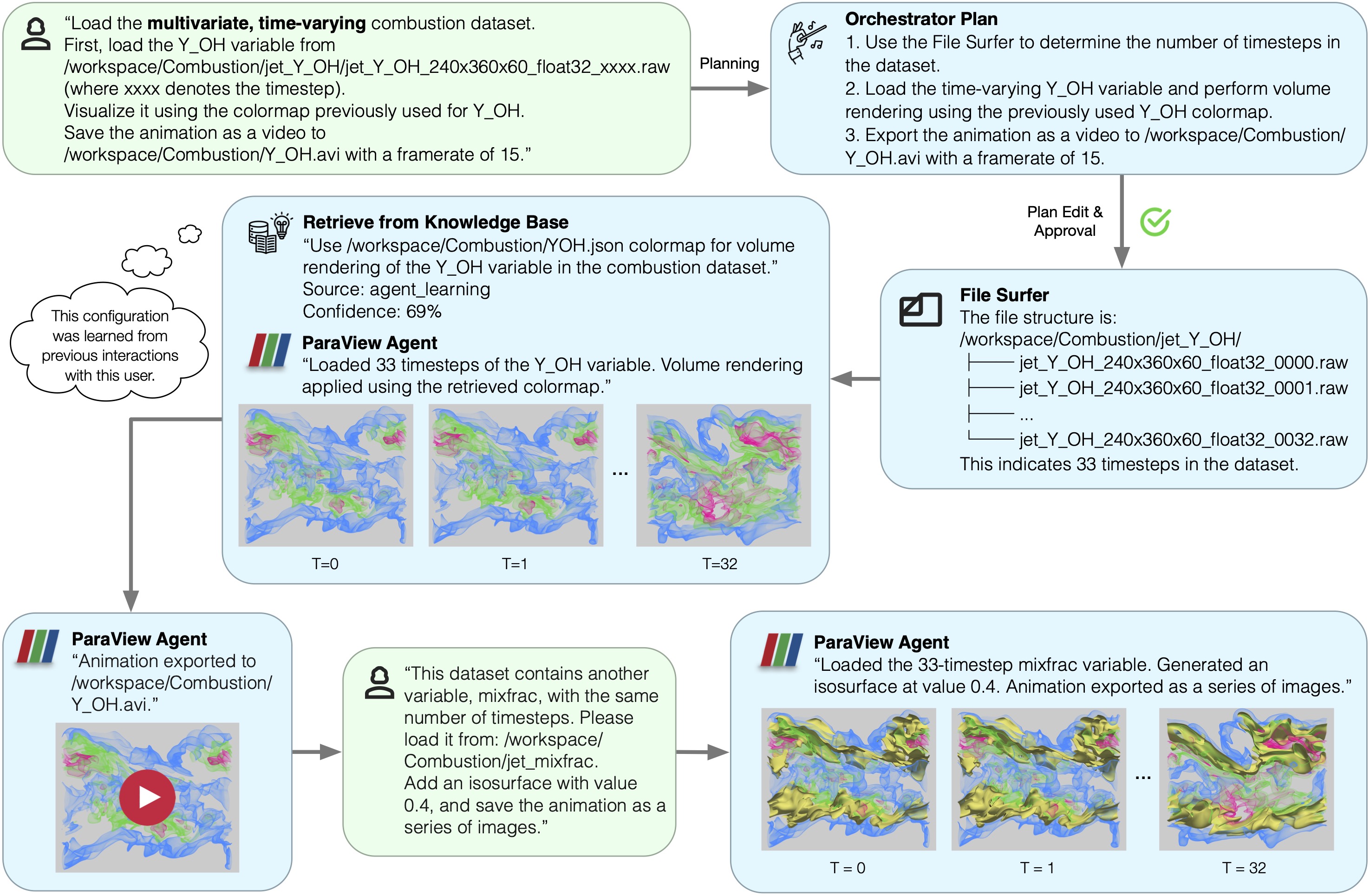
Overview of HiLSVA. An orchestrator interprets user intent, builds explicit stepwise plans, and coordinates specialized agents (ParaView, code, file surfer, web surfer) with bidirectional human–agent interaction, provenance-aware workflows, sandboxed execution, and a self-improving agent that adapts during inference.